
MAGA:面向垂类场景的知识图谱增强问答系统
一、研究背景
随着近年来预训练模型研究的飞速发展,其在问答、搜索、智能创作等场景下展现出了越来越强的通用性。如何让模型学会用好外部知识,是下一阶段预训练语言模型发展的重要难题之一。近年来,知识图谱结合预训练的工作取得了新的进展。现有工作较多使用静态的知识图谱,在输入或监督层面增强语言模型。而业界的知识图谱往往持续演化,具有更大的规模、更丰富的内容、细分的垂直领域、且包含丰富的新实体与新关系。微信有着丰富的多模态文章与视频数据场景,并构建了持续更新的大规模知识图谱。如何训练语言模型来有效地与知识图谱进行联动,将图谱作为资源库,从而利用其中的新知识与垂类知识(包含结构化知识、无结构化文本、多模态知识等),是一个重要且富有挑战的难题。该项目旨在进一步探索知识指导的语言模型技术,形成高质量学术论文及可落地的模型与系统。
二、研究问题
核心研究问题为如何联合优化语言模型与知识图谱表示,提升模型对于新语料、新实体的表示能力,提升困难样本上的泛化效果,即语言模型与知识图谱的联合训练(Joint Learning of Language Models and Knowledge Graphs)。该问题又可拆分为以下子问题:
(1)统一范式的生成式预训练语言模型
要利用好外部知识,首先要基于一套具有迁移学习能力的统一范式的预训练语言模型,即只需要通过较少的提示机制(prompt)等方法就可以整合若干序列到序列生成任务的模型。自2022年12月以来,以GPT为代表的自回归模型独领风骚,但对于利用外部知识、图谱花知识、结构化或半结构化知识、以至于多模态知识,GPT是否仍然是最优的选择,是值得深入深入研究的。
生成式预训练语言模型(GPT1.0)打开了NLP领域以同一模型适配若干任务的大门,通过调节输入形式即可完成针对下游任务的训练,为后来的统一范式的GPT3.0和T5模型奠定了基础。GPT1.0的范式符合人们一般认为的语言学习的规律:先学习大量语料获得相应的认识基础,再对具体任务进行特殊的构造和优化。
在GPT模型提出不久就加入精调产生了GPT2。GPT2模型较前代的预训练语料库为超过40G的近8000万的网页文本数据,GPT2的预训练语料库相较于GPT而言增大了将近10倍。在模型方面,GPT-2 仍保持着简单的架构,只使用了多个 Masked Self-Attention 和 Feed Forward Neural Network 两个模块。
GPT和GPT2与另一种生成式预训练模型BERT的主要区别是方向。BERT 是基于双向 Transformer 结构构建,而 GPT和GPT2 是基于单向 Transformer,这里的双向与单向,是指在进行注意力计算时,BERT会同时考虑被遮蔽词左右的词对其的影响,而 GPT和GPT-2 只会考虑在待预测词位置左侧的词对待预测词的影响。
OpenAI所提出的GPT总的来说采用的是自回归生成的学习任务在推动模型的表示学习,但是Google所提出的T5(Text-to-Text Transfer Transformer)模型采用了一种与前述模型相异的策略:将不同形式的任务统一为条件生成式任务,这样以来预训练模型的学习任务与下游具体任务的训练方式就统一起来了,即可以使用统一的编码-解码方式来进行预训练和其他自然语言处理任务,不需要上述针对具体任务具体构造。这种模型称为“大一统”模型,可以有效降低不同任务之间的迁移学习与多任务学习的难度。
(2)知识增强的方案的优化
单纯基于问答语料构建的预训练语言模型存在两个重要缺陷:事实性错误和逻辑关系不可寻迹。
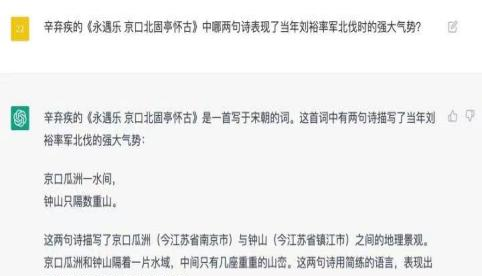
图1 chatGPT的事实性错误与逻辑关系不可寻迹
在不同的问答、搜索、智能创作等场景下,具有不同规模、不同类型内容、不同细分垂直领域的图、文、视频等多模态信息。如何训练语言模型来有效地与知识图谱进行联动,对于预训练语言模型来说,本质上就是如何构造不同的预训练任务。将知识图谱嵌入(Knowledge Graph Embedding, KGE)、知识图谱补全(Knowledge Graph Completing, KGC)等任务转化为预训练任务是一个重要的研究内容。
理论上,利用知识实现对预训练语言模型的增强有两种思路:一类是直接传入图结构(Factoid Knowledge Graph),或者保留已有的图结构加入问答文本,之后利用路径推理(path based symbolic methods)等方法利用知识,该方案较早成熟,问答效果下限高、上限低,可解释性较好;另一类是不保留图结构,而是将知识图谱嵌入一个低维稠密空间(KGE),利用该空间分布式表示KG中的实体、关系,甚至是事件等,该方案提出是在word2vec等方案出现之后,但发展迅速,对嵌入训练预料要求高,问答效果下限较低、上限很高,稳健性较强。
利用KGE的方案可以再分成三种:一种是利用知识图谱嵌入(KGE)作为掩码,另一种是利用知识图谱嵌入作为特征,第三种是两者结合。
两者结合方面有代表性的模型包括百度的ERNIE系列模型(也即文心系列)及其问答模型PLATO(Bao, 2019)系列模型(包括其前身AKGCM)。PLATO模型先后发表在EMNLP(前身KAGCM, 2019)、ACL(1.0,2020),并且都在Github上以paddlepaddle框架的形式开放调用。相关领域的研究者或可以在遵循paddle框架的基础上继续训练。
利用KGE作为特征的方案有很多变种,最重要的变种应该是引入多任务方法,将KGE训练和QA共同作为PLM的训练任务。考虑到后续方法极大扩展了KGE-QA的适用性,将单独放在下一节多源异构融合中。
(3)基于多智能体的强化学习问答系统
chatGPT使用PPO算法来增强问答系统的人类反馈,对于知识增强的预训练模型该方案是否仍然是最优的,多智能体框架是否能成为更有潜力的人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF),即以强化学习方式依据人类反馈优化语言模型。
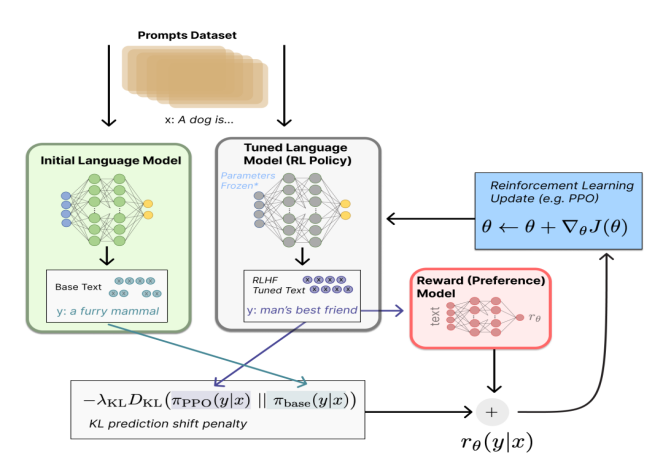
图2 基于PPO的RLHF方法
过去几年里各种 LLM 根据人类输入提示 (prompt) 生成多样化文本的能力令人印象深刻。然而,对生成结果的评估是主观和依赖上下文的,例如,我们希望模型生成一个有创意的故事、一段真实的信息性文本,或者是可执行的代码片段,这些结果难以用现有的基于规则的文本生成指标 (如 BLUE 和 ROUGE) 来衡量。除了评估指标,现有的模型通常以预测下一个单词的方式和简单的损失函数 (如交叉熵) 来建模,没有显式地引入人的偏好和主观意见。
这就是 RLHF 的思想就是利用生成文本的人工反馈作为性能衡量标准,或者更进一步用该反馈作为损失来优化模型:使用强化学习的方式直接优化带有人类反馈的语言模型。RLHF 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。
附录:用户端测试版(SaaS)
用户端测试版(MAGA1.0)
本文作者系何轶辉(21级应统)
本文编辑系赵晨宇(22级信管)